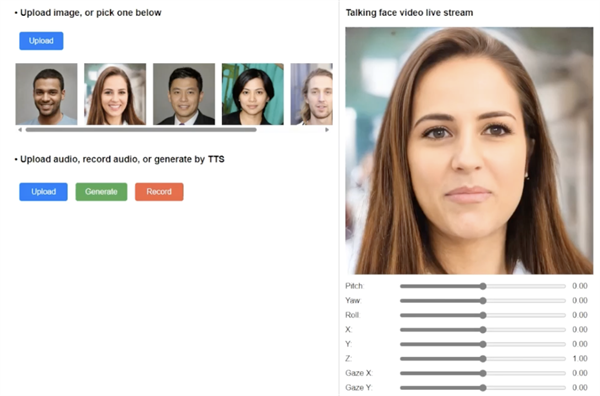
导读:卡饭网 4 月 22 日消息,微软公司近日发布新闻稿,正式揭晓了其创新的图生视频技术—— VASA-1 框架。这一 AI 框架仅需凭借一张真实的肖像照片和一段个人语音音频,便能打造出精确且逼真的对口型视频(即生成朗诵文本的视频)。 当前业界…
本文地址: https://www.life0731.com/read-400249.html
免责声明:本文仅代表作者个人观点,与长沙生活网(本网)无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
本网站有部分内容均转载自其它媒体,转载目的在于传递更多信息,并不代表长沙生活网(本网)赞同其观点和对其真实性负责,若因作品内容、知识产权、版权和其他问题,请及时提供相关证明等材料并与我们联系,本网站将在规定时间内给予删除等相关处理.